The Latent Dirichlet Allocation (LDA) algorithm is a text mining algorithm that aims to extract topics from long texts. In a nutshell, LDA assumes that each document defines a distribution over topics, and each topic defines a distribution over words. Each word is generated by first sampling a topic from the document, and then sampling a word from the topic. To train an LDA is to solve for the parameters of these two distributions (doc-topic and topic-word) given many documents; To evaluate an LDA usually means predicting the topic distribution for a new unseen document.
This article will introduce LDA in a top-down fashion: Starting with the NeurIPS paper example, it first formulates topic modeling as a parameter estimation problem; then comes some essential math tools (e.g. Dirichlet distribution, Gibbs sampling, etc.); and finally, derives the LDA training and testing algorithms.
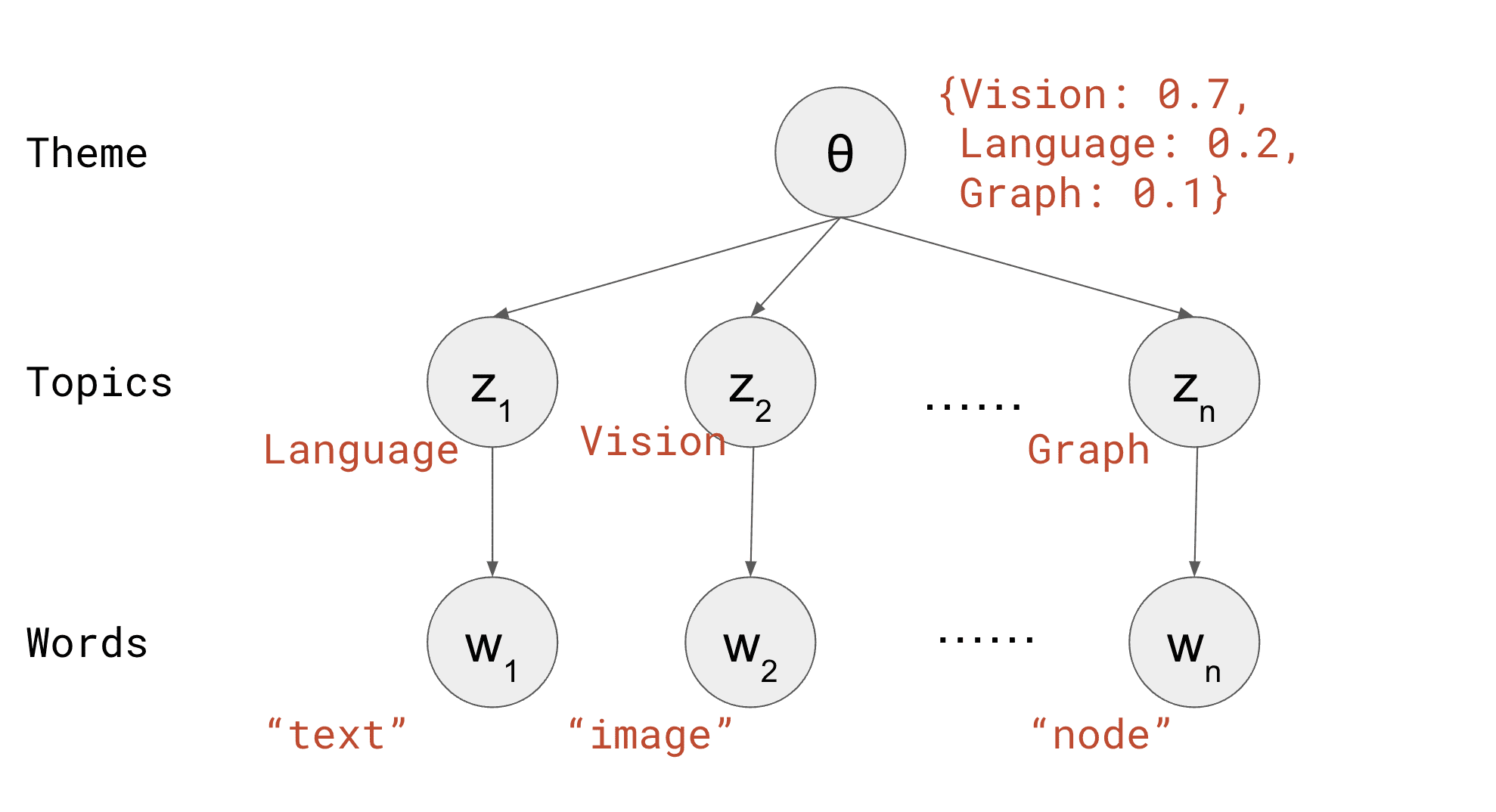
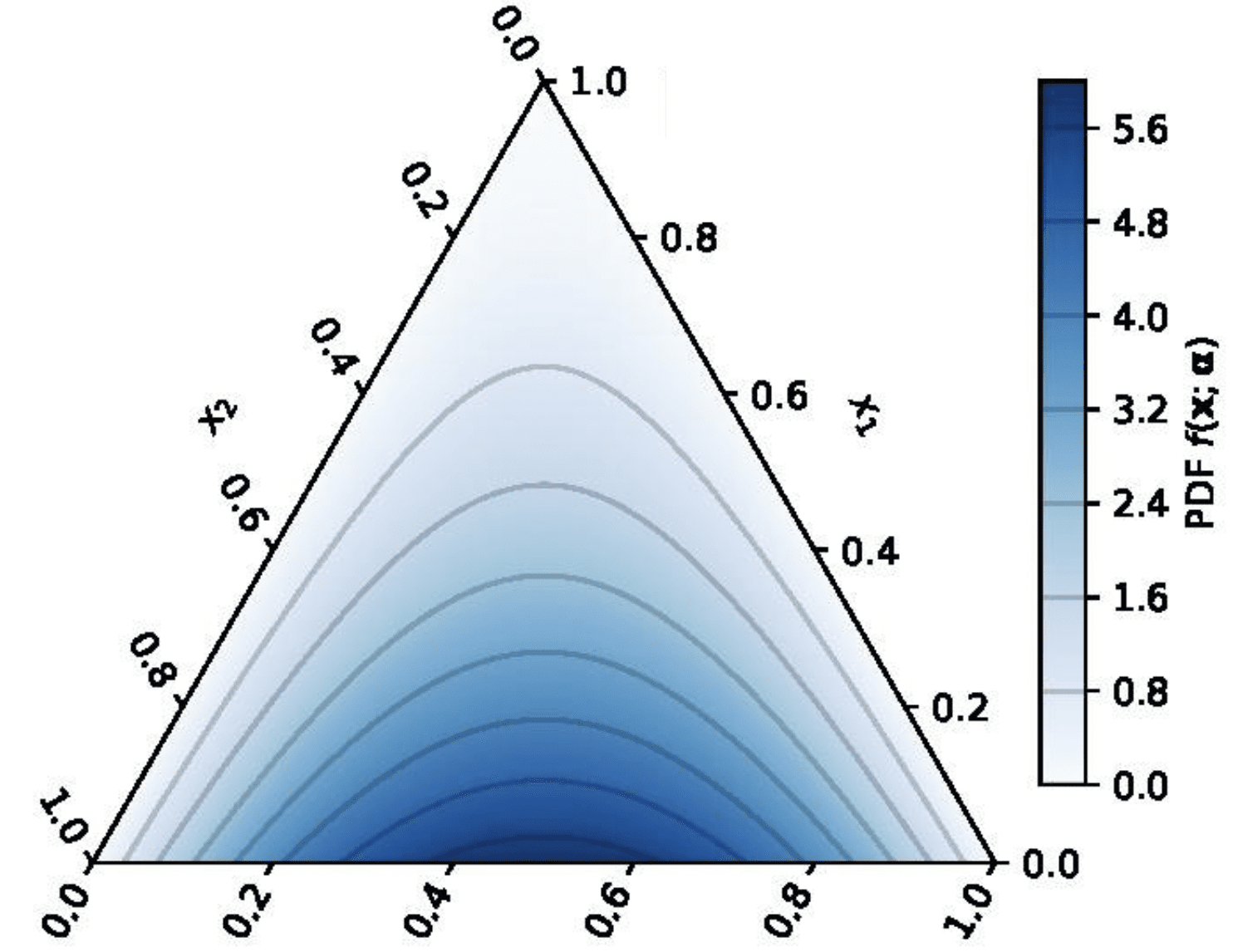
Imagine you are analyzing papers published in a machine learning conference. There are M=1000 accepted papers, and each paper has a N=200 word abstract. The conference has K=3 topics: vision, language, and graph. In order to analyze which topics each paper addresses, you make the following assumptions:
Each paper defines a theme, which is a distribution over topics, e.g.
1
{Vision: 0.7, Language: 0.2, Graph: 0.1}
Each topic defines a distribution over words (same for all papers), e.g.
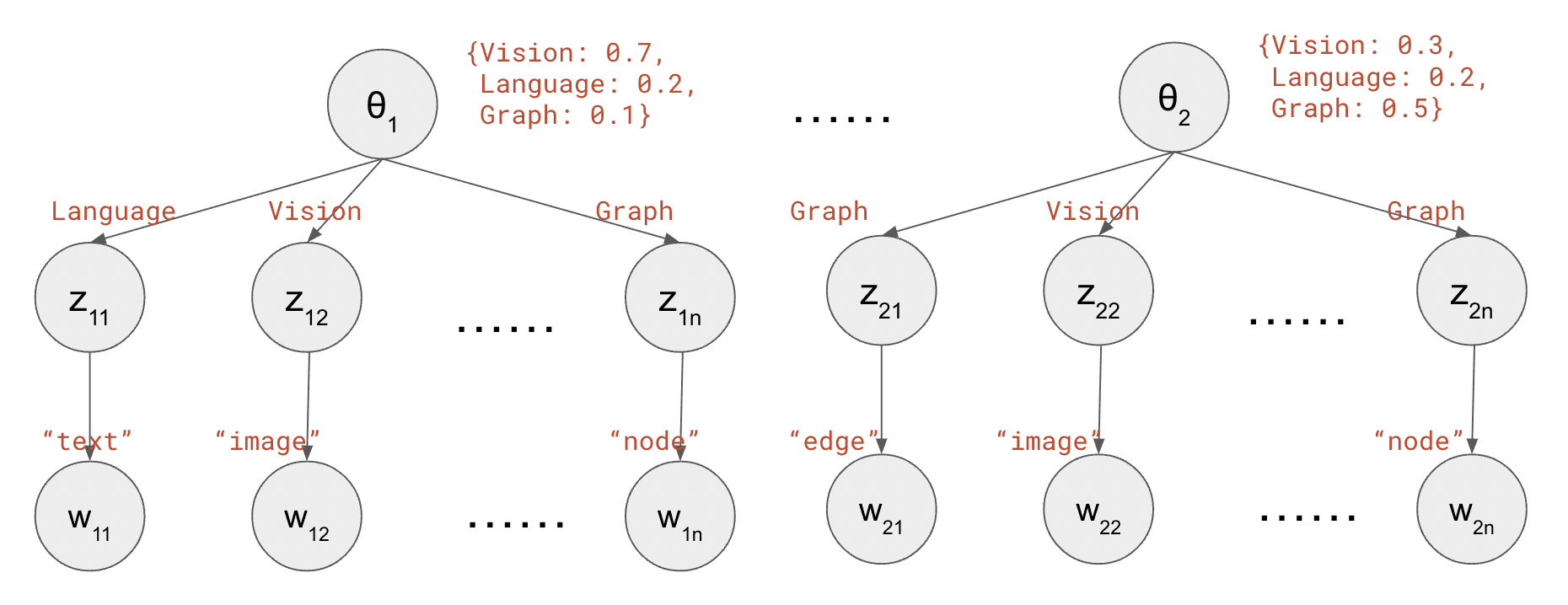
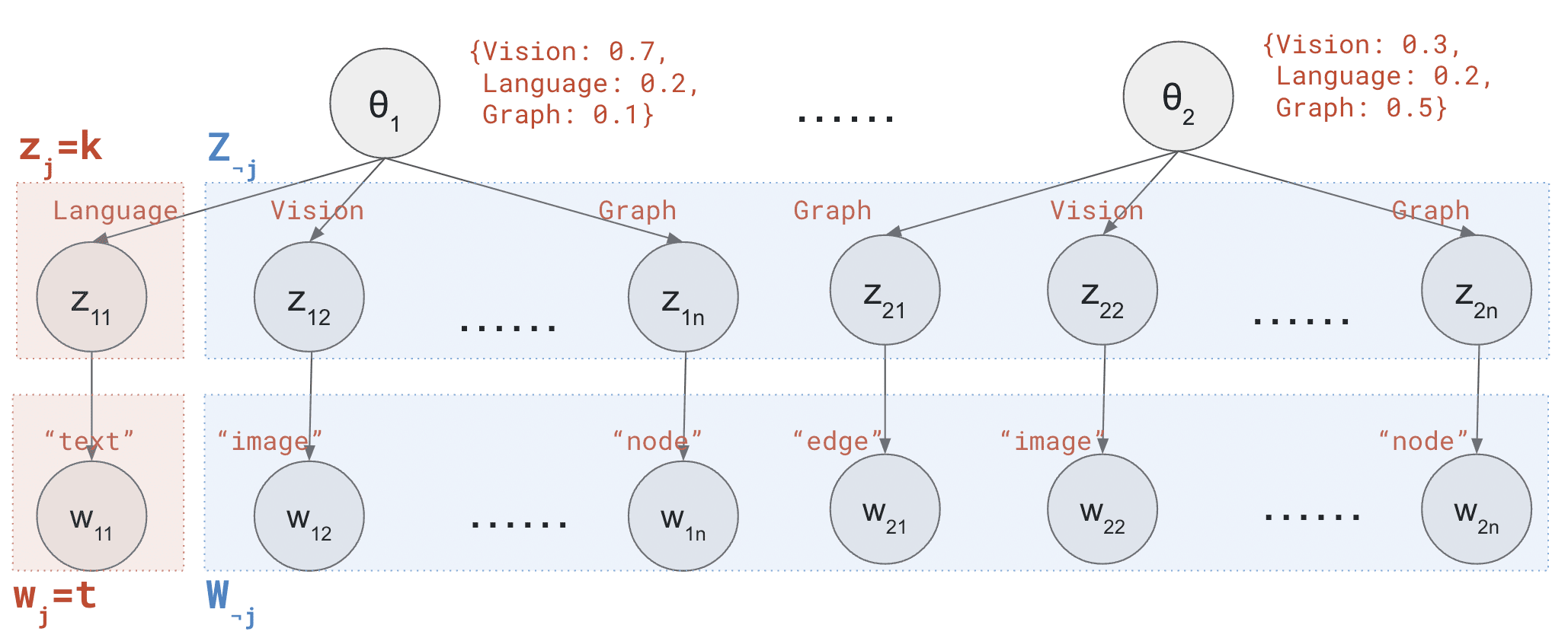
The words in the papers are generated using the following procedure (as illustrated in the figure below):
for m = 1…M // loop across documents
Randomly generate a themeθ, e.g. {Vision: 0.7, Language: 0.2, Speech: 0.1}
for n = 1…N // loop across words
Randomly generate a topicz according to the theme, e.g. Vision
Randomly generate a wordw according to the topic, e.g. "image"
Generating words in one paper according to the LDA model. Inspired by CS 221 course note [3]
During LDA training, we are interested in solving the following 2 problems:
Finding the topic distribution for each of the M existing papers (Θ∈RM×K);
Finding the word distribution for each of the K topics (Φ∈RK×V, where V is the vocabulary size);
We can then use these two matrices in LDA testing:
Given a new unseen paper, find its topic distribution (θnew∈RK).
The Dirichlet distribution 101
Prior, data, and posterior
Let’s take a closer look at the parameters we want to solve: the topic distribution for each of the M documents (Θ) and the word distribution for each of the K topics (Φ). In order to estimate them, the LDA algorithm makes some assumptions about their prior. What is a prior? It’s our belief about the parameters without observing the data. In contrast, after you observe the data, you get the posterior. Usually we are interested in the posterior, since it incorporates the information of data and therefore is good for estimating the parameters using methods like MAP (maximum-a-posteriori) or EAP (expectated-a-posteriori).
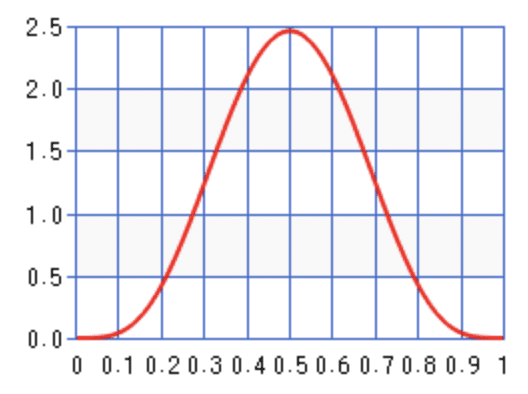
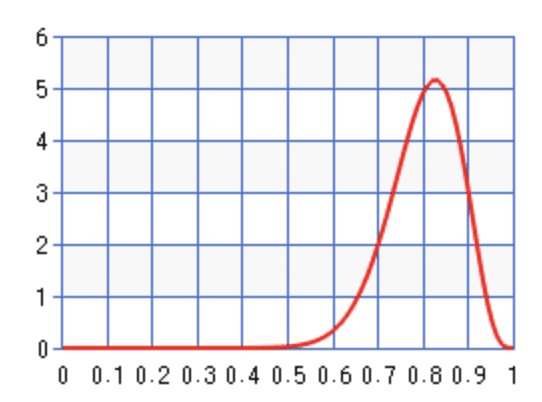
Here’s an example: Imagine you have a coin which you believe to be a fair coin, so you may think its probability of showing head is most likely around 0.5 (prior P(pcoin)). However, after tossing it several times, it always shows head (data). Therefore your belief about its head probability gradually shifts from 0.5 to very close to 1 as the evidence accumulates (posterior P(pcoin∣data)). In this example, both the prior and the posterior of the coin’s probability can be nicely modeled with the Beta distribution. We can either report the expectation or the maximum of the posterior to answer the question “What do you think is the probability of coin after observing several tosses?”
Example prior P(pcoin)
Example posterior P(pcoin∣data) after tossing and observing heads only
Similarly, given a paper, we may have a prior that its topic distribution is most likely symmetric, e.g. {Vision: 1/3, Language: 1/3, Graph: 1/3} (prior P(θ)). Similar to the coin, you may imagine this as a three-sided dice. After reading the paper through, you never encountered a single word about graphs, which means for 99% of the time you are seeing words like “image”, “captioning”, “text”, and so on (data W). At this moment your belief about its topic ratio (the probability of the dice) may shift towards something like {Vision: 0.5, Language: 0.5, Graph: 0.0} (posterior P(θ∣W)). In this example, both the prior and the posterior can be nicely modeled with the Dirichlet distribution. We can either report the expectation or the maximum of the posterior to answer the question “What do you think is the topic distribution of the paper after reading it through?”
Example prior P(θ)
Example posterior P(θ∣data) after observing only vision and language related words in the paper
Note that in the above two examples, the Beta/Dirichlet distribution aren’t our only choice. We choose them mainly because they are mathematically convenient, for if the prior is Beta/Dirichlet, then the posterior is also Beta/Dirichlet. This algebraic convenience is frequently referred to as the “conjugate prior”.
The Dirichlet Distribution: Jar of dices
We’ve been using sloppy terms like “belief” to describe the following intuitions:
A prior/posterior is a distribution that models the probability density of the estimated parameter. If we make the analogy that the topic distribution of a paper (a.k.a the “theme”) is like a K-sided dice, then the Dirichlet distribution is just like a jar of dices. Each time you reach in (which we call “sampling”), you get a new dice. In the paper example, before you observe the data, the jar is considered to be more likely to give you a fair dice; After you observe the data, the jar is considered to be more likely to give you a biased dice.
The expectation of the posterior shifts as you accumulate more data. This is roughly equivalent to sampling from the jar many times and taking the average of the dices you get.
Now let’s take a closer look at the Dirichlet distribution, our jar of dices.
Recall that, a “dice” refers to a multinomial distribution Mult(p1,...,pn) with ∑i=1npi=1 and pi≥0. A jar of dices is then a multivariate distribution over n variables p=[p1,...,pn], where ∑pi=1 and pi≥0. And remember our ultimate goal is to estimate the dice by solving for the posterior, which is the jar after observing some data.
So, what is the data? Intuitively, the best way to collect data in order to estimate a dice, is to toss it many times and count the occurrences of each outcome. Here’s an example: Imagine you toss a three-sided doc-topic dice 100 times, and this is what you get:
Vision: 50 (50%)
Language: 40 (40%)
Graph: 10 (10%)
And suppose your prior is that the dice should be fair. The most naive way to incorporate this belief, is to add a “pseudo-count” to your observation. The amount of “pseudo-count” depends on the strength of your prior: If you really think the dice should be as fair as possible despite the observation, then you probably want to add a large pseudo-count (e.g. 100) to your data, which pulls the expectation of the posterior much closer to a fair dice:
Vision: 50+100 (37.5%)
Language: 40+100 (35%)
Graph: 10+100 (27.5%)
Otherwise you may want to add a tiny bit of pseudo-count (e.g. 1), which perturbs the observation by a small amount:
Vision: 50+1 (49.5%)
Language: 40+1 (39.8%)
Graph: 10+1 (10.7%)
And it turns out the Dirichlet distribution respects this pseudo-count intuition: It is parameterized by a parameter α={α1,...,αn}, where each αi can be regarded as the pseudo-count for the i-th outcome of the dice. We denote the Dirichlet distribution as P(p;α), which means it’s a distribution with regard to the dice probabilities p and parameterized by the pseudo-count α. It has the following two nice properties:
The Dirichlet posterior Dir(p∣x;α) after observing data x=[x1,...,xn] (xi being the occurrences of the i-th outcome) is a new Dirichlet distribution incorporating the prior’s pseudo-count with the observed data, which makes it straightforward to compute the posterior:
Dir(p∣x;α)=Dir(p;α+x)
The expectation of a Dirichlet prior Dir(p;α) is equal to the ratios between the αis, which makes it straightforward to estimate the value of the parameter from a Dirichlet posterior:
We are not going to dive into too much details, e.g. the definition of the Dirichlet distribution can be found here, and there are several interpretations for the intuition behind its density function [3]. However, to me I found it helpful to just regard it as a convenient math tool invented adhoc to model the jar of dices (i.e. the distribution of Multinomial distributions). And surprisingly, the LDA algorithm will not make use of its density function; A solid grasp of the above two properties is sufficient.
Back to our problem
Now going back to our problem: The parameters to estimate can be imagined as M doc-topic dices (each with K faces, as in Θ∈RM×K) and K topic-word dices (each with V faces, as in Φ∈RK×V). The M doc-topic dices share the same prior, while the K topic-word dices share the other prior.
Extending our analogy: Imagine there are 2 jars of dices, one jar filled with doc-topic dices, from which you randomly take M of them (Θ={θ1,...,θM}, where each θm is a K-dim distribution over topics). These become the topic distributions of the M documents; Another jar filled with topic-word dices, from which you randomly take K of them (Φ={φ1,...,φK}, where each φk is a V-dim distribution over words). These become the word distributions of the K topics.
Our goal is to estimate the values of Θ and Φ by solving for their posteriors and taking the expectations:
doc-topic dices Θ
topic-word dices Φ
prior
Dir(α), where α is a hparam
Dir(β), where β is a hparam
data
The number of words with each topic (e.g. 100 words under Vision, 200 words under Language, 300 words under Graph)
The occurrences of different words generated by the same topic (e.g. for topic Vision, “image” appeared 10 times, “recognition” appeared 20 times, etc.)
posterior
to be solved by LDA
to be solved by LDA
The LDA model
Problem formulation
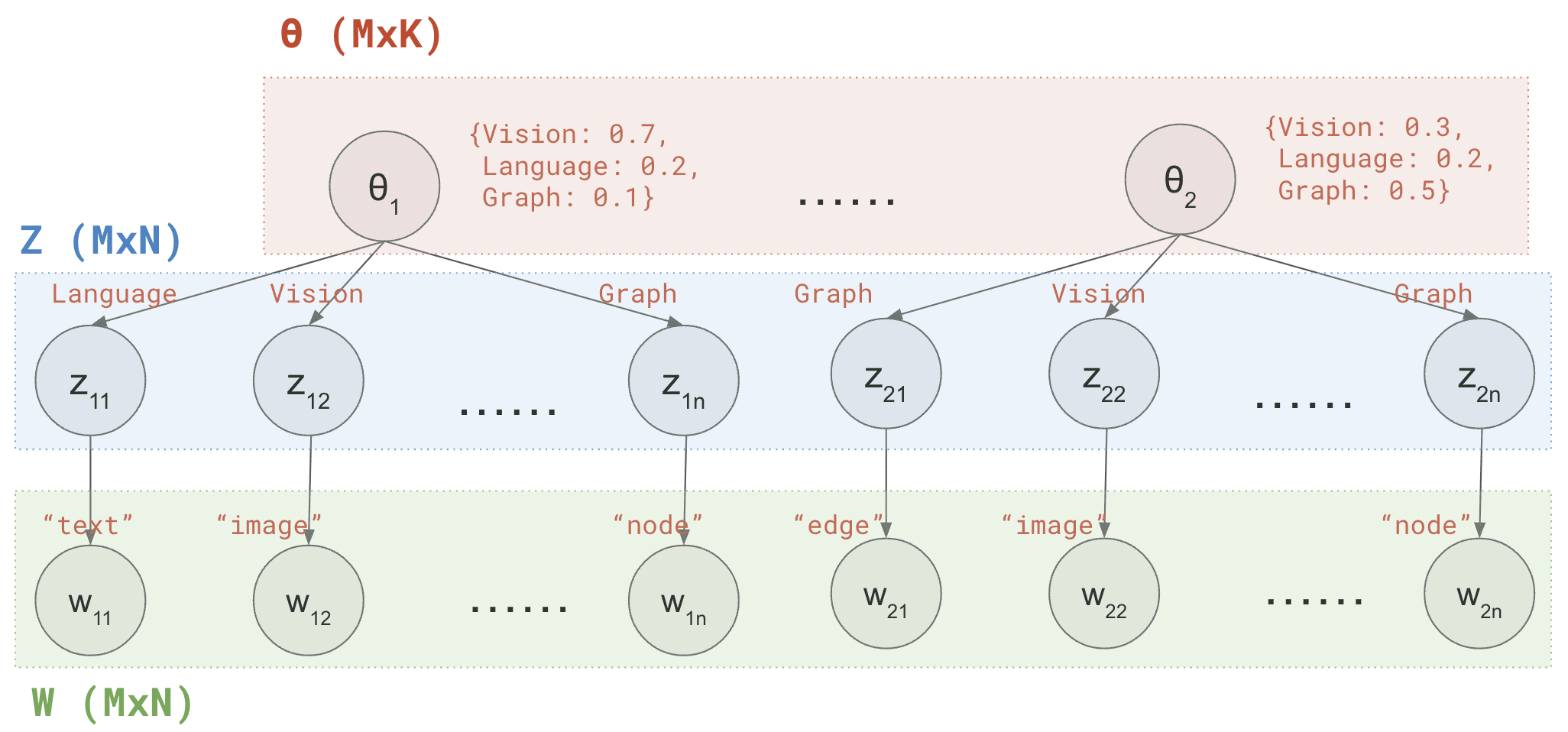
Now refining the random sampling parts in our initial pseudo-code, we can summarize the LDA generative procedure as follows (see the figure below for an example):
// initializing the M doc-topic dices and the K topic-word dices
for m = 1…M // loop across documents
Randomly sample a doc-topic dice θm∼Dir(α)
// K-dim probability distribution over all topics,
// e.g. {Vision: 0.7, Language: 0.2, Speech: 0.1}
for k = 1…K // loop across topics
Randomly sample a topic-word dice φk∼Dir(β)
// V-dim probability distribution over all words,
// e.g. {"image": 0.05, "recognition": 0.01, "detection": 0.01, ...}
// Generate the words
for m = 1…M // loop across documents
for n = 1…N // loop across words
Randomly sample a topic zmn∼Mult(θm)
// Integer in {1,...,K} representing a topic, e.g. Vision
Randomly sample a word wmn∼Mult(φzmn)
// Integer in {1,...,V} representing a word, e.g. "image"
Our goals are as follows:
For the train set documents, infer the latent variables Θ, Φ (i.e. the M doc-topic dices and the K topic-word dices) from the observed words W (The Dirichlet prior α,β are hyperparameters of the LDA model) by taking the expectation of the posterior:
Θ^Φ^=E[P(Θ∣W;α,β)]=E[P(Φ∣W;α,β)]
For an unseen test document with words Wnew, infer its latent variable θnew (remember we sample a new doc-topic dice for each document, but reuse the topic-word dices for all documents. Therefore we only need to infer a new θ, not φ). This can be achieved by computing the expectation of the posterior:
θnew^=E[P(θnew∣W∪Wnew;α,β)]
The hidden variable Z
How do we estimate the posterior of Θ and Φ? Well, remember we discussed that it’s straightforward to compute the Dirichlet posteriors as long as we have the data handy:
doc-topic dices Θ
topic-word dices Φ
prior
Dir(α), where α is a hparam
Dir(β), where β is a hparam
data
The number of words with each topic (e.g. 100 words under Vision, 200 words under Language, 300 words under Graph)
The occurrences of different words generated by the same topic (e.g. for topic Vision, “image” appeared 10 times, “recognition” appeared 20 times, etc.)
posterior
to be solved by LDA
to be solved by LDA
The problem is that we don’t really know which topic is behind each word! If you are familiar with the EM algorithm, you’d probably know this is called a “hidden variable”. Here, the topic variable Z∈RM×N (One topic for each of the N words in each of the M documents) is crucial for computing the posterior (see the table above), yet it’s unknown to us. One way to bypass this challenge, is to sample the value of Z given the words W∈RM×N:
Z∼P(Z∣W)
The intuition here is that we want to know which topics are most likely given the words we see, and thus using them to estimate the parameters would make the most sense. And here we make the approximation of using one sample of Z to represent the average scenario of all possible Zs. Nowadays, this is a strategy widely adopted by neural networks with stochastic components (e.g. VAEs).
Mathematically, we can dive deeper to see why sampling Z from P(Z∣W) makes sense. The reader may refer to the appendix for a more in-depth explanation (warning: math ahead).
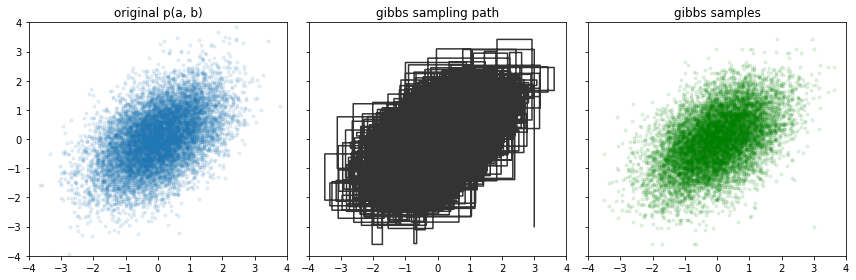
Gibbs Sampling
But how do you generate samples from a distribution? Simple as it may seem, this isn’t a trivial question. That being said, there are many well-developed algorithms that does exactly this. Gibbs sampling is the one we will use here because it’s mathematically convenient under the LDA framework. We’ll introduce the algorithm here without explaining why it works, but interested readers may refer to this tutorial (or: section 0.4 of [3] if you read Chinese).
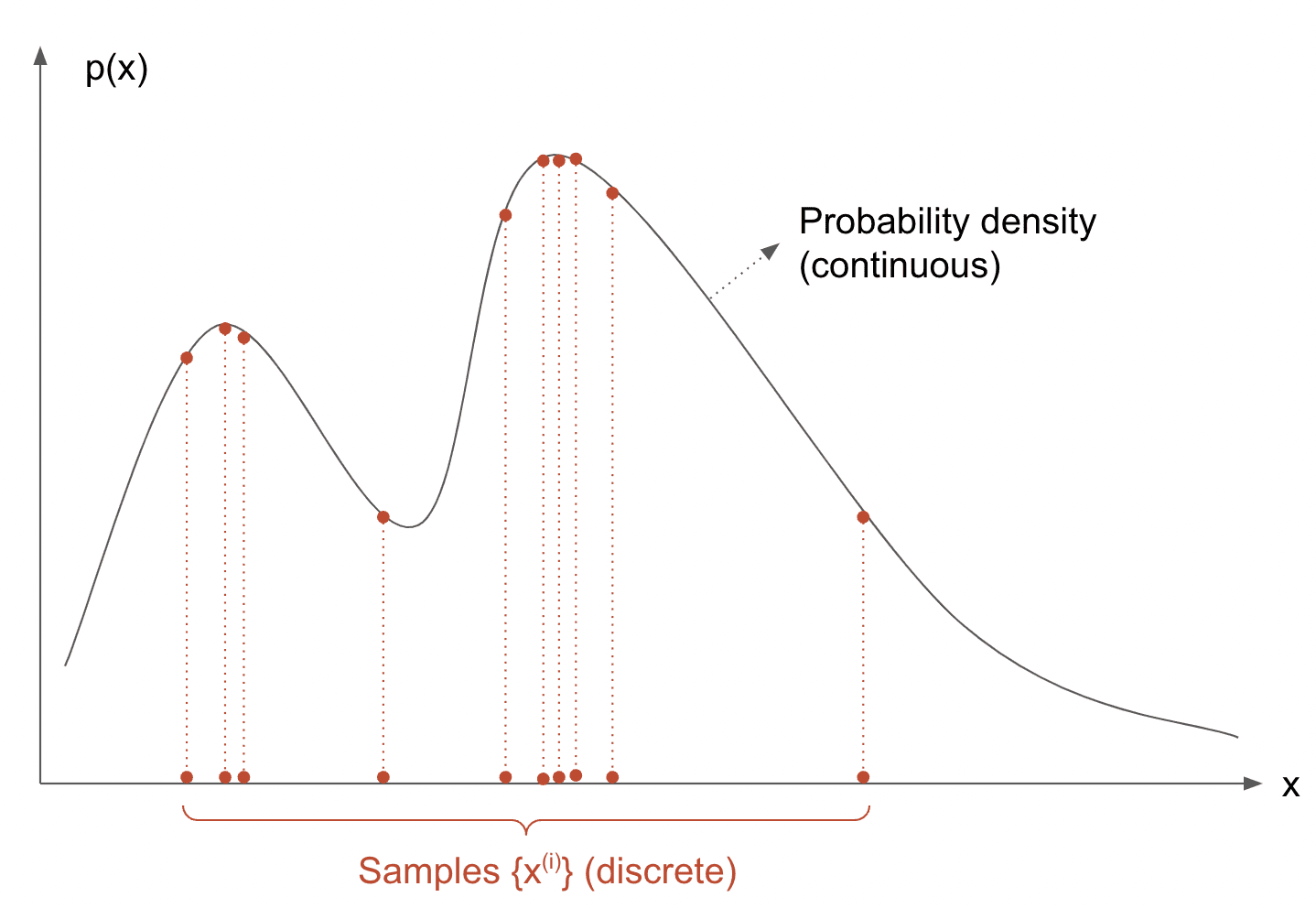
Input: The math equation of p(x). That is, for any given x, we know how to compute its probability; This, however, doesn’t always make it feasible to compute statistics like expecatation/variances, which usually requires an integral and can be intractable in practice.
Output: Samples {x(1),x(2),...,x(T)} drawn from p(x). We can then make use of these samples to approximate the statistics we are interested in, e.g. the expectation as the average across all samples.
Sampling from a probability distribution.
// random initialization for x(0)∈RD
[x1(0),x2(0),...,xD(0)]←random vector
// iterative sampling
for t in 0…T // repeat while not converged
for d in 1…dim(x): // loop through the dimensions of x
In one sentence, what (*) does is: Freeze the values of all other dimensions, and sample the current dimension according to their values. For instance, in 2D, Gibbs sampling alternates between sampling x while freezing y, and sampling y while freezing x:
And in the 3D scenario, each Gibbs sampling iteration (i.e. the inner loop) is equivalent to:
x1(t+1)x2(t+1)x3(t+1)∼P(⋅∣x2(t),x3(t))// freeze x2,x3, only sample x1∼P(⋅∣x1(t+1),x3(t))// freeze x1,x3, only sample x2∼P(⋅∣x1(t+1),x2(t+1))// freeze x1,x2, only sample x3
LDA Training
Recall that, as mentioned at the beginning of this article, the goal of LDA training is to estimate Θ and Φ given the words we see, which requires sampling Z from P(Z∣W). Let’s do it with Gibbs sampling.
As you probably already noticed, the only tricky part is the (*) line, which means “Freezing the values of all the other dimensions, and sampling the current dimension according to their values.” For sampling Z, this means “freezing the topics of all the other words, and sampling the topic of the current word.” This can be written as:
zj∼P(zj=k∣Z¬j,W)
Which means, to sample the topic for the j-th word in the corpus (we can imagine “flattening” the corpus by concatenating the words in each of the papers into a long word list, and the index j runs through this long word list), we hold the topics for all the other words (Z¬j) fixed.
And if we go a little further, each step of the Gibbs sampling process can be transformed into…
P(zj=k∣Z¬j,W)// P(A|B) ∝ P(A, B) when B is observed.∝P(zj=k,wj=t∣Z¬j,W¬j)// Marginalize over θ and φ by taking the integral.=∫θm∫φkP(zj=k,wj=t,θm,φk∣Z¬j,W¬j)dθmdφk// The above probability corresponds to the product of the following events:// 1) θm is sampled from the posterior Dirichlet distribution given Z¬j,W¬j;// 2) Topic k is sampled from θm with probability θmk;// 3) φk is sampled from the posterior Dirichlet distribution given Z¬j,W¬j;// 4) Word t is sampled from φk with probability φkt;=∫θmθmkP(θm∣Z¬j,W¬j)dθm⋅∫φkφktP(φk∣Z¬j,W¬j)dφk// The above two integrals are equivalent to computing the following two expectations:=E[θmk∣Z¬j,W¬j]⋅E[φkt∣Z¬j,W¬j]// Recall that the posteriors of Θ and Φ are Dirichlet distributions,// whose parameters are the sum between the pseudo-counts α, β and the observed counts.// So we count the co-occurrences between the M documents and the K topics NM×K,¬j,// and the co-occurrences between the K topics and the V words NK×V,¬j,// and use them to calculate the expectation of the Dirichlet posterior.// The ¬j subscription means that we exclude word j from the co-occurrences.=∑k′(αk′+Nmk′,¬j)αk+Nmk,¬j⋅∑t′(βt′+Nkt′,¬j)βt+Nkt,¬j(∗∗)
This part is quite dense. In plain English, what this does is: Repeat until converge: Loop through each word, for each word, you count the doc-topic and topic-word co-occurrences without taking into account the current word and its topic; Re-sample the topic of the current word according to (**). In the end, the sequence of the values of the variable Z generated by Gibbs sampling will be samples of P(Z∣W).
For estimating the parameters Θ and Φ, we can either take the average between multiple samples, or just approximate with one sample. If we go with one sample, then the estimation for Θ^,Φ^ will be:
by computing the expectation of their Dirichlet posteriors – combining the pseudo-counts with the observed counts. Here, after the sampling, Nmk refers to the count of words with topic k in document m; Nkt refers to the co-occurrence between word t and topic k in the entire corpus. For Θ, we are combining the pseudo-count α with the observed doc-topic co-occurrences; For Φ, we are combining the pseudo-count β with the observed topic-word co-occurrences.
We may also optionally take multiple samples of Z, use them to estimate Θ and Φ separately, and take the average in between. This would take more computational resources, but could provide a less biased estimation.
LDA Testing
The goal of LDA testing is to estimate the topic distribution θnew given a new document. The only difference as compared to LDA training, is that the evidence is now W+Wnew, and all we need to do is to sample the topics for each word in the new document. The Gibbs sampling formula changes to:
Where, Nk,¬j refers to the count of words with topic k in the new document (excluding the j-th word), and Nnew,kt,¬j refers to the co-occurrence of word t with topic k in the new document (excluding the j-th word).
The estimation for θnew would be (where Nk refers to the count of words with topic k in the new document, after we are done with the topic sampling):
We use the NeurIPS papers dataset from this Kaggle competition, which contains the content of the accepted NeurIPS papers ranging between 1987 to 2016. We select the earliest 1000 papers and the latest 1000 papers respectively and train 2 separate LDA models. I’m particularly interested in one question: “How do the topics of NeurIPS shift over the course of ~30 years?”
For each paper, I keep the first 200 words from the abstract, and limit the size of the vocabulary to be 10000. I set the number of topics to be K=10, as I expect the NeurIPS conference to have some level of topic diversity but not too much.
LDA Training
Here, I’ll show the result for the topic-word dices Φ as it’s usually of higher interest to us – what topics are present in the corpus? What does each topic look like?
The 19xx papers
Here are the 10 topics and their top 10 words for the earliest 1000 papers (in other words, they are published in the 20th century). The deeper the color is, the more weight the word has in the corresponding topic:
We can roughly see what most of the topics correspond to (note that this interpretation is purely subjective!):
Topic 0: training ML models
Topic 1: math symbols / circuit design
Topic 2: signal processing
Topic 3: reinforcement learning
Topic 4: neural networks
Topic 5: kernel methods
Topic 6: speech recognition
Topic 7: biological inspiration for neural networks
Topic 8: computer vision
Topic 9: probability theory / bayesian networks
The 20xx papers
Here are the 10 topics and their top 10 words for the latest 1000 papers (so they are published around 2016):
And we can also try to interpret the meaning of each topic, however this time we can’t explain them super well:
Topic 0: training deep neural networks
Topic 1: general machine learning
Topic 2: (?)
Topic 3: generative models (GAN/VAE)
Topic 4: neural networks
Topic 5: (?)
Topic 6: (?)
Topic 7: reinforcement learning
Topic 8: graph analysis
Topic 9: computer vision
It’s interesting to see that some topics remain popular after ~30 years, e.g. reinforcement learning and computer vision; Some topics aren’t as popular as they were, e.g. kernel methods; Finally, some topics gain increasing popularity nowadays, e.g. graph analysis.
LDA Testing
Given a new unseen paper, the LDA testing aims to find its topic distribution. Here, I’ll give an example of using the LDA model trained on the 19xx papers to predict the topics of an unseen 19xx paper:
1 2 3 4
Title: Decomposition of Reinforcement Learning for Admission Control Abstract: This paper presents predictive gain scheduling, a technique for simplifying reinforcement learning problems by decomposition. Link admission control of self-similar call traffic is used to demonstrate the technique. The control problem is decomposed into on-line prediction of near-future call arrival rates, and precomputation of policies for Poisson call arrival processes. At decision time, the predictions are used to select among the policies. Simulations show that this technique results in significantly faster learning without any performance loss, compared to a reinforcement learning controller that does not decompose the problem.
The predicted topics consist of the following K=10-dim vector (recall that this is the θnew):
where, each number corresponds to one of the topics. The top topic is Topic 3 (with a weight of 60%+), which aligns with our intuition that this paper is highly relevant to reinforcement learning.
Closing Thoughts
When I began learning the LDA algorithm in my junior year, I started with the most well-known and comprehensive tutorial in Chinese: LDA Math Gossip (LDA数学八卦) [3]. It is a great tutorial if you are purely interested in math and absolutely not in a hurry to understand and to implement LDA for your project. While I truly appreciate that the tutorial assumes no prior knowledge of stats ML and explains every component of the algorithm with great clarify, I got distracted by the amount of details/proofs that could have been treated as a black box without much harm. It was so hard to keep track of all the variables and their contexts, that when I first read it, I was completely lost. I needed to frequently go back and forth to answer the tons of questions popping into my mind: What is phi? Why are you sampling Z in order to estimate phi? Wait what is Z again? And so on. I believe this struggle isn’t unique and it becomes the motivation to write this article.
At the same time, I believe these problems are inevitable if the tutorial is written in a bottom-up fashion. It’s like showing every single pixel at the beginning and gradually zooming out. I try to do the reverse – showing the picture at the beginning and gradually zooming in. The downside is that I can’t go as deep and rigorous into the math as LDA Math Gossip does, which might be unsatisfactory for some readers, but my hope is that it’ll be more friendly to engineers like me, especially to those looking for some intuition about the algorithm, but can’t afford much time to go through all the details.
In order to compute the expectation for Θ and Φ, we need to marginalize upon the joint probability distribution P(Θ,Φ,Z∣W):
Θ^=EΘ[P(Θ,Φ,Z∣W)]// This is how expectation is defined...=Z∑∫Θ∫ΦΘ⋅P(Θ,Φ,Z∣W)⋅dΘdΦ// P(A,B,C) = P(A|B,C) P(B|C) P(C)=Z∑∫Θ∫ΦΘ⋅P(Θ∣Z,W)⋅Φ’s estimation only depends on Z and WP(Φ∣Z,W,Θ)⋅P(Z∣W)⋅dΘdΦ// Turns out Θ and Φ are conditional independent given Z and W,// because the posterior of Θ (doc-topic dices) can be estimated solely based on Z, // which determines the topic distribution of each document; // The posterior of Φ (topic-word dices) can be solely estimated from Z and W, // which determines the word distribution of each topic.=Z∑∫Θ∫ΦΘ⋅posterior of doc-topic dicesP(Θ∣Z,W)⋅posterior of topic-word dicesP(Φ∣Z,W)⋅P(Z∣W)⋅dΘdΦ// Recall that the posteriors of Θ and Φ are Dirichlet distributions,// whose parameters are the sum between the pseudo-counts α, β and the observed counts.// So we count the co-occurrences between the M documents and the K topics NM×K,// and the co-occurrences between the K topics and the V words NK×V,// which yields the Dirichlet posterior of Θ and Φ as follows:=Z∑∫Θ∫ΦΘ⋅Dir(Θ∣α+NM×K])⋅Dir(Φ∣β+NK×V)⋅P(Z∣W)⋅dΘdΦ// Just re-arranging, nothing special...=Z∑P(Z∣W)⋅=EΘ[Dir(Θ∣α+NM×K)]∫ΘΘ⋅Dir(Θ∣α+NM×K])dΘ⋅=1∫ΦDir(Φ∣β+NK×V)dΦ// The first integral is the expectation of Θ, and the second integral sums up to 1.=Z∑P(Z∣W)⋅EΘ[Dir(Θ∣α+NM×K)]// The expectation of Dir(⋅) is the (normalized) ratio between its parameters. =intractableZ∑P(Z∣W)⋅trivial to compute given Z[N^mk=∑k′(αk′+Nmk′)αk+Nmk]M×K
The integral w.r.t. Θ,Φ are feasible to compute once we have Z – since we are trying to find the posterior of doc-topic and topic-word dices, and that we’ve assumed their priors to be Dirichlet, we can just incorporate our observation – the occurrences of topics in a document and words with a topic, with the pseudo-count – α and β, to get the parameters of the Dirichlet posterior. And since we know how to compute the expectation of Dirichlet distributions (which is itself, an integral in the same form), these two parts aren’t of much concern.
The real trouble is the summation over all possible values of Z! Since Z is a (M×N)-dim discrete variable (remember it’s the topic of each word) with K possible values for each dimension, an exhaustive enumeration would be intractable. Is there any chance we can bypass the exhaustive enumeration over Z?
The tool we use the intractability, is “sampling”. In computer science, a common practice to model complicated distributions, is to generate samples of it. That is to say, if you are interested in some very complicated distribution p(x), then you probably want to generate a large amount of samples xi∼p(x). Now if you wish to compute some attributes of the distribution, e.g. its expectation E[p(x)], you can simply take the average of your samples as a reasonable approximation. Otherwise, we’d need to take an integral to calculate the expectation precisely, which is typically intractable in practice.
Given n samples [Z1,Z2,...,Zn] (or, sometimes if our computation resources are really limited, we may even just go with one example, which means n=1) drawn from P(Z∣W), we’d be able to approximate
Z∑P(Z∣W)f(Z)≈n1i=1∑nf(Zi)
here, f(Z) can be any function of Z. In our calculation of EΘ[P(Θ∣W)] above, we have f(Z) equal to ∑k′(αk′+Nmk′)αk+Nmk.
So the next question becomes how do we generate samples from a distribution, which goes back to the Gibbs sampling section 😃