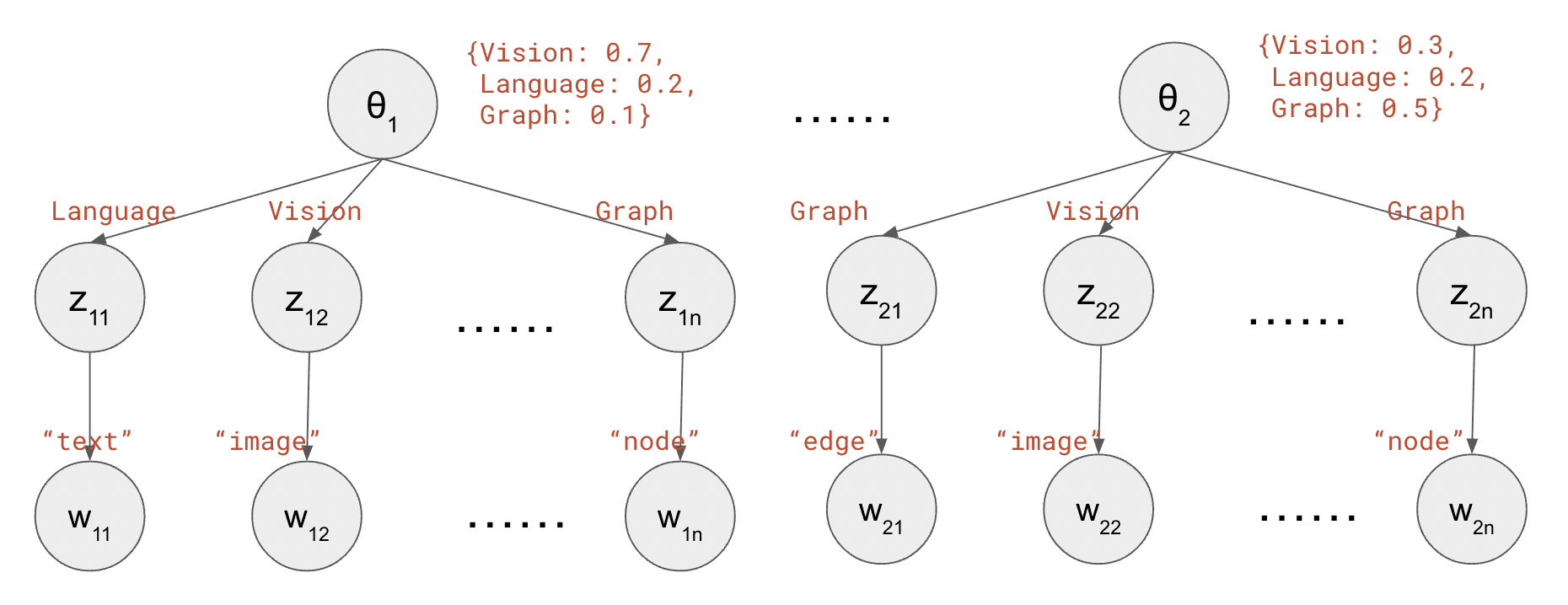
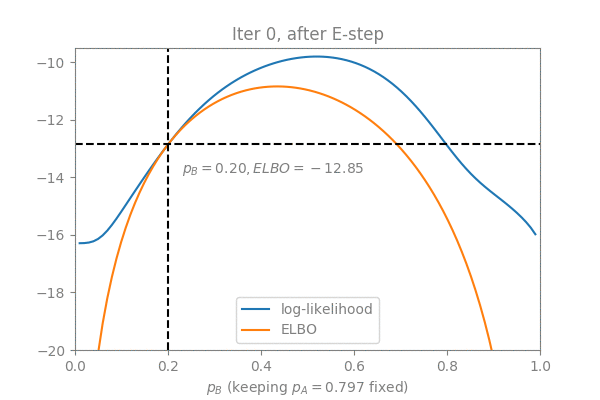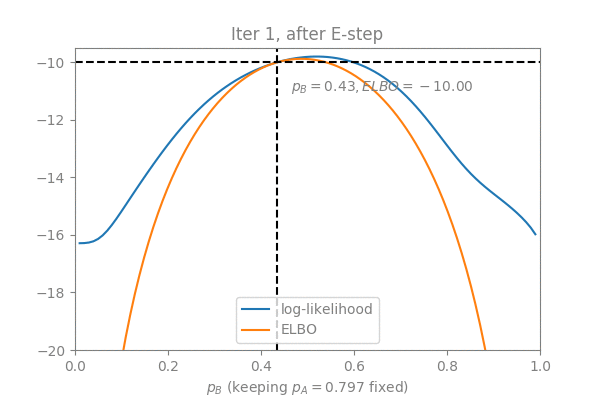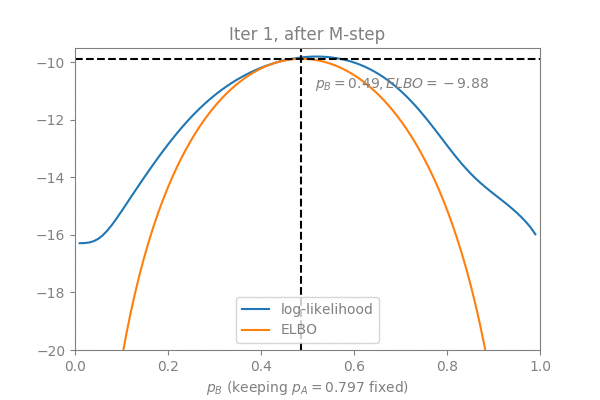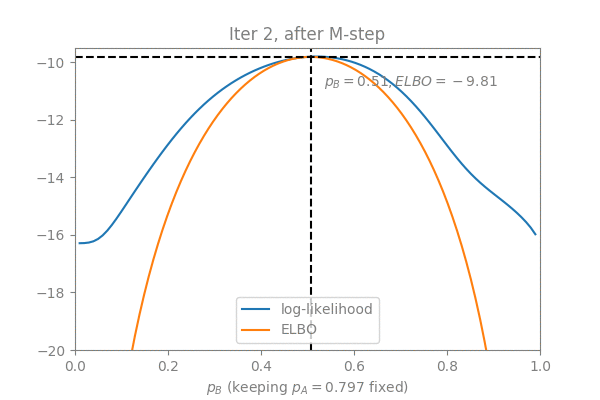
The Latent Dirichlet Allocation (LDA) algorithm is a text mining algorithm that aims to extract topics from long texts. In a nutshell, LDA assumes that each document defines a distribution over topics, and each topic defines a distribution over words. Each word is generated by first sampling a topic from the document, and then sampling a word from the topic. To train an LDA is to solve for the parameters of these two distributions (doc-topic and topic-word) given many documents; To evaluate an LDA usually means predicting the topic distribution for a new unseen document.